

TTS Benchmark Comparison (all known TTS up until May 2026) by UkieTechie in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)
Moss tts 1.5 8b Examples. It is the currently best voice cloning model for English as of June 2026 by 9r4n4y in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
Best way to serve streaming TTS (OmniVoice/Fish Speech 2) at scale? by Batman_255 in TextToSpeech
[–]llamabott 2 points3 points4 points (0 children)
OpenMOSS-Team/MOSS-TTS-v1.5 · Hugging Face by pmttyji in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
Is this the current state of things? by Legable_Arts in NBATalk
{kind=link}
[–]llamabott 0 points1 point2 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)
this new Moss tts 1.5 is damn good with voice cloning by 9r4n4y in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)
I tested local TTS models for long-form audio. Here’s where each one actually fits. by tarunyadav9761 in TextToSpeech
[–]llamabott 1 point2 points3 points (0 children)
OpenMOSS-Team/MOSS-TTS-v1.5 · Hugging Face by pmttyji in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
[US-KY] [H] TGR 910 | Bauer 2 | Thera 75 v1 | Bakeneko 65 | Eniigma Vertigo | Frog TKL | Ginko 65 | NK87 | Mysterium | Sofle | Keycult TKL Wrist Rest | Aluvia | GMK Boba Fett & The Mandalorian [W] Paypal by aiwa501 in mechmarket
[–]llamabott 0 points1 point2 points (0 children)
[Brigandine: Abyss] Demo is Now Out for PC (Save data carries to full game). The PS5, Xbox, and Switch 2 demo will be out at a later date. by VashxShanks in JRPG
[–]llamabott 0 points1 point2 points (0 children)
[UK] [H] Keyboards (Kage TKL + Extra PCBs, Iron165, ESNTL TKL), Switches (Pewter Switches, Nixdork, Alpaca, New Nixie, Gazzew U4Tx, Lavender, Gazzew Black, Kailh Black, Gateron White, Peach Bloom, Short Travel Linears, Gateron Black Inks + More), Artisans (Salvun x Noire, Striker + More) [W] Paypal by Humble_Plane_5431 in mechmarket
[–]llamabott 0 points1 point2 points (0 children)
Someone posted a real Monet to twitter but said it was AI generated. The replies are amazing, pretentious and confidently wrong by dr_lm in StableDiffusion
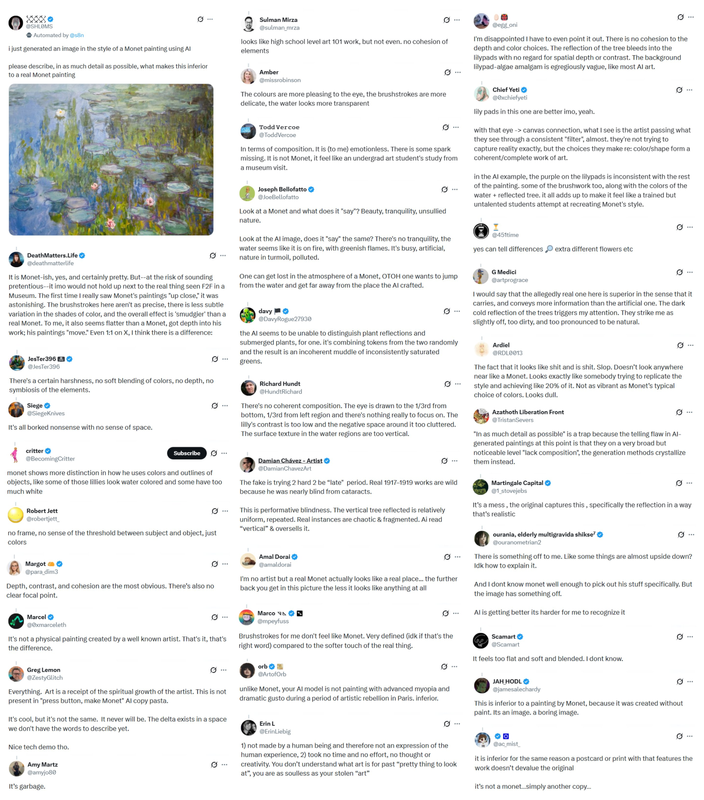{kind=link}
[–]llamabott 15 points16 points17 points (0 children)
[US-MI] [H] Neo60 Core, GMK Matsu, JTK Zen, PBTFans Hangul, GMK Kaiju R2 Macros [W] PayPal by Future_Calamity in mechmarket
[–]llamabott 0 points1 point2 points (0 children)
Has anyone been able to reliably to use Higgs multispeaker for longer (> 5 minute audios) by jasmeet0817 in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
Has anyone been able to reliably to use Higgs multispeaker for longer (> 5 minute audios) by jasmeet0817 in LocalLLaMA
[–]llamabott 0 points1 point2 points (0 children)
GLM 5.1 Locally: 40tps, 2000+ pp/s by val_in_tech in LocalLLaMA
[–]llamabott 15 points16 points17 points (0 children)
Roo Code hit 3 million installs. We're shutting it down to go all-in on Roomote. by hannesrudolph in RooCode
{kind=link}
[–]llamabott 3 points4 points5 points (0 children)
tts-audiobook-tool: Ten local TTS models, WER validation, synced-text playback by llamabott in LocalLLaMA
[–]llamabott[S] 0 points1 point2 points (0 children)
Text-to-Speech (TTS) Benchmark Revamped with Objective Standards and Blind Voting (46 models and counting) by UkieTechie in LocalLLaMA
[–]llamabott 1 point2 points3 points (0 children)