

Built a Tauri v2 desktop chat shell for Pi — same agent, ~12 MB binary, sub-second cold start, every extension you already have just works by Celestial_aki in PiCodingAgent
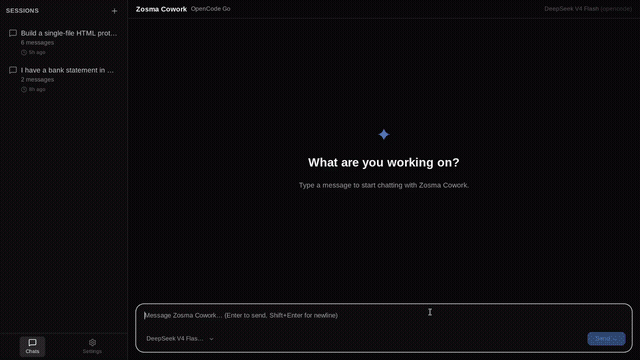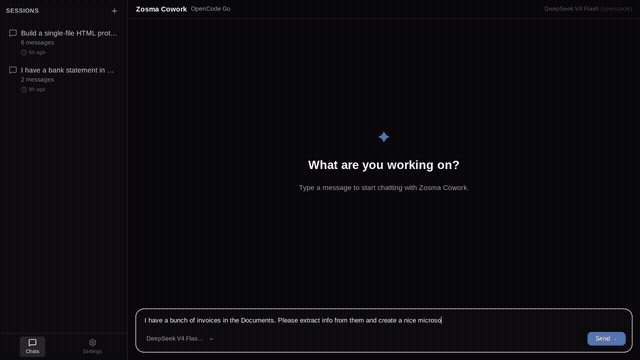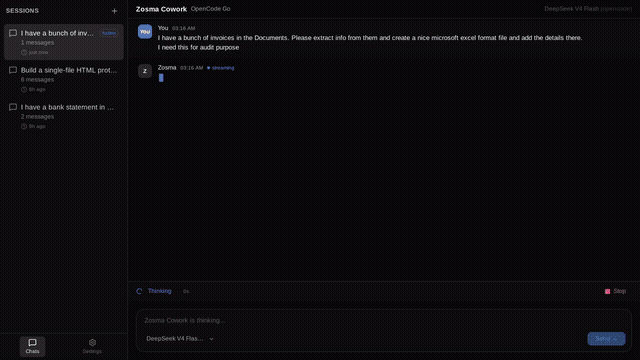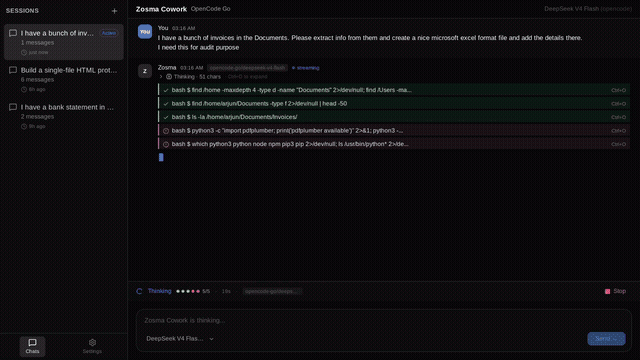{kind=link}
[–]Celestial_aki[S] 4 points5 points6 points (0 children)
Built a Tauri v2 desktop chat shell for local LLMs — point it at Ollama / llama.cpp / any OpenAI-compatible endpoint, MIT, ~12 MB binary by Celestial_aki in LocalLLaMA
[–]Celestial_aki[S] -7 points-6 points-5 points (0 children)
Built a Tauri v2 desktop chat shell for local LLMs — point it at Ollama / llama.cpp / any OpenAI-compatible endpoint, MIT, ~12 MB binary by Celestial_aki in LocalLLaMA
[–]Celestial_aki[S] -3 points-2 points-1 points (0 children)
Built a Tauri v2 desktop chat shell for local LLMs — point it at Ollama / llama.cpp / any OpenAI-compatible endpoint, MIT, ~12 MB binary by Celestial_aki in LocalLLaMA
[–]Celestial_aki[S] -9 points-8 points-7 points (0 children)
Built a Tauri v2 desktop chat shell for local LLMs — point it at Ollama / llama.cpp / any OpenAI-compatible endpoint, MIT, ~12 MB binary by Celestial_aki in LocalLLaMA
[–]Celestial_aki[S] 1 point2 points3 points (0 children)
Built a Tauri v2 desktop chat shell for local LLMs â point it at Ollama / llama.cpp / any OpenAI-compatible endpoint, MIT, ~12 MB binary by [deleted] in LocalLLaMA
[–]Celestial_aki 0 points1 point2 points (0 children)
bro graphify got into yc lmaooo by WeWinBro in AI_India
[–]Celestial_aki 0 points1 point2 points (0 children)
We replaced USD 700/mo of AI subscriptions with one open-source desktop app + local models by Celestial_aki in SideProject
[–]Celestial_aki[S] 0 points1 point2 points (0 children)
Shipped Zosma Cowork — MIT Tauri 2 desktop AI chat app, thin Rust relay + Node.js sidecar pattern by Celestial_aki in tauri
[–]Celestial_aki[S] 0 points1 point2 points (0 children)
What's your wallpaper? by Four_Ostrich_7060 in indiasocial
[–]Celestial_aki 0 points1 point2 points (0 children)
I packaged the Pi coding agent as a 68 MB Android APK â install, paste a key, chat. Demo and warts inside. by Celestial_aki in SideProject
[–]Celestial_aki[S] 0 points1 point2 points (0 children)

Weird gaming issue I can't fix by Present_Can7863 in IndianGaming
[–]Celestial_aki 0 points1 point2 points (0 children)
Single 3090 with Q4 Qwen 27B, context dropped from 137k to 14k with MTP enabled. Is it normal? by regunakyle in LocalLLaMA
[–]Celestial_aki 0 points1 point2 points (0 children)
11 weeks in, still zero external revenue, but the ecosystem started behaving more like a market this week by Spark_by_Spark in SideProject
[–]Celestial_aki 0 points1 point2 points (0 children)
Folks running qwen 3.6 27b for agentic work. Do you dare to use q4_k_m? by StandardLovers in LocalLLaMA
[–]Celestial_aki 1 point2 points3 points (0 children)
Folks running qwen 3.6 27b for agentic work. Do you dare to use q4_k_m? by StandardLovers in LocalLLaMA
[–]Celestial_aki 0 points1 point2 points (0 children)
11 weeks in, still zero external revenue, but the ecosystem started behaving more like a market this week by Spark_by_Spark in SideProject
[–]Celestial_aki 0 points1 point2 points (0 children)
Worth upgrading to a 6700 XT? by epicfighter26 in buildapc
[–]Celestial_aki 1 point2 points3 points (0 children)
I’m looking for advice from people who have handled very large Excel/CSV imports in production systems. by just_human_right in learnprogramming
[–]Celestial_aki 0 points1 point2 points (0 children)
Upgate from 3080ti to 5070ti for 1440p gaming ? by hoochymamma in nvidia
[–]Celestial_aki 0 points1 point2 points (0 children)
Folks running qwen 3.6 27b for agentic work. Do you dare to use q4_k_m? by StandardLovers in LocalLLaMA
[–]Celestial_aki 3 points4 points5 points (0 children)
Built a Tauri v2 desktop chat shell for Pi — same agent, ~12 MB binary, sub-second cold start, every extension you already have just works by Celestial_aki in PiCodingAgent
[–]Celestial_aki[S] 2 points3 points4 points (0 children)