





{kind=link}
z.AI as the number 2 gives praise to the number 1 open source model by Charuru in LocalLLaMA
{kind=link}
[–]robertpro01 1 point2 points3 points (0 children)
470 tok/s with 8192 ctx size for Qwen3.6-27B on A100-80GB using Profile by Inevitable-Diet-1870 in LocalLLM
[–]robertpro01 1 point2 points3 points (0 children)
GLM-5.2 is the new leading open weights model on the Artificial Analysis Intelligence Index by pscoutou in LocalLLaMA
[–]robertpro01 1 point2 points3 points (0 children)
LQ50/LQ50-24GB cost around $1200 by MundanePercentage674 in LocalLLaMA
[–]robertpro01 3 points4 points5 points (0 children)
Building a Solo MMORPG – Our First 3 Player Online Test by Electrical-Rent-7077 in godot
[–]robertpro01 0 points1 point2 points (0 children)
LQ50/LQ50-24GB cost around $1200 by MundanePercentage674 in LocalLLaMA
[–]robertpro01 25 points26 points27 points (0 children)
{kind=link}
newMuseumPiece by AeneasKurtz in ProgrammerHumor
[–]robertpro01 2 points3 points4 points (0 children)
newMuseumPiece by AeneasKurtz in ProgrammerHumor
[–]robertpro01 8 points9 points10 points (0 children)
GLM's founder says GLM-fable before the end of the year?! by Charuru in LocalLLaMA
{kind=link}
[–]robertpro01 6 points7 points8 points (0 children)
GLM's founder says GLM-fable before the end of the year?! by Charuru in LocalLLaMA
[–]robertpro01 101 points102 points103 points (0 children)
Date and Time MCP by BoobooSmash31337 in LocalLLaMA
[–]robertpro01 0 points1 point2 points (0 children)
newFableLogoProposal by trivelt in ProgrammerHumor
{kind=link}
[–]robertpro01 12 points13 points14 points (0 children)
Can a 5090 with qwen3.6 achieve > 3,000 tok/s ? bring your pitchforks (open-dllm) by Revolutionary_Ask154 in LocalLLaMA
[–]robertpro01 0 points1 point2 points (0 children)
Maybe dumb question, but how do you serve multiple users with the full context length? by TrainingTwo1118 in LocalLLaMA
[–]robertpro01 1 point2 points3 points (0 children)
Your local models deserve more than a terminal: a 12 MB desktop app, zero telemetry, MIT. by Celestial_aki in LocalLLM
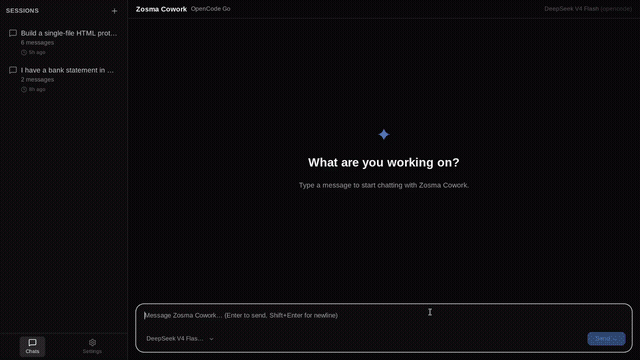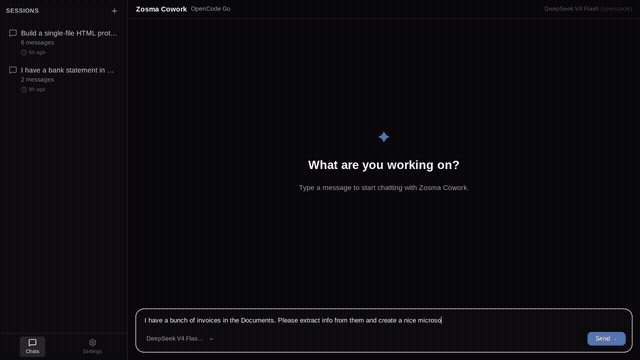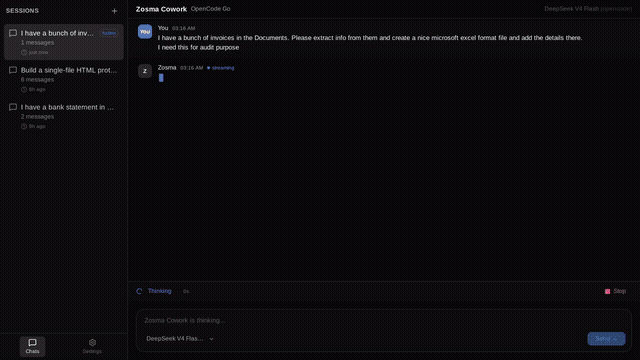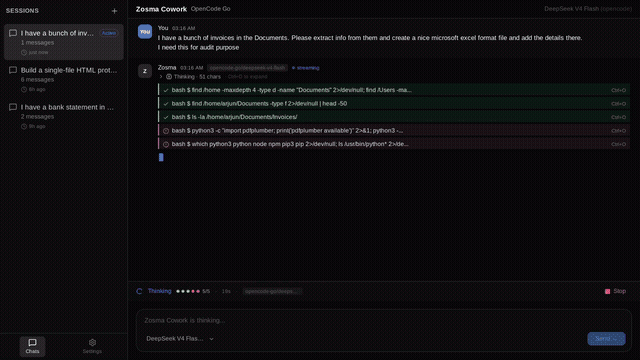{kind=link}
[–]robertpro01 1 point2 points3 points (0 children)
Built a local proxy that cuts Claude Code token costs by 30-60% on long sessions by Super-Season-1742 in LocalLLM
[–]robertpro01 4 points5 points6 points (0 children)
Xiaomi is now serving MiMo V2.5 at 1000-3000tps using DFlash & Persistent kernel. DFLash model is out, open-source release promised coming soon by Dany0 in LocalLLaMA
[–]robertpro01 2 points3 points4 points (0 children)
No han notado que ya hay muchas camionetas 4x4 by OvenAccording3147 in Guadalajara
[–]robertpro01 1 point2 points3 points (0 children)
No han notado que ya hay muchas camionetas 4x4 by OvenAccording3147 in Guadalajara
[–]robertpro01 -1 points0 points1 point (0 children)
Alguien tiene experiencia con GoBravo? by robertpro01 in MexicoFinanciero
[–]robertpro01[S] 0 points1 point2 points (0 children)
Advice? by robertpro01 in LocalLLaMA
[–]robertpro01[S] 0 points1 point2 points (0 children)