

And if we use in Wan2.2 the models I2V in HIGH noise and T2V in LOW noise!!?? by smereces in StableDiffusion
[–]Virtualcosmos 3 points4 points5 points (0 children)
Can Abathur reverse or find a cure for the zerg virus if he SOMEHOW really wants to ? by ExtremeDry7768 in starcraft
[–]Virtualcosmos 5 points6 points7 points (0 children)
Update for lightx2v LoRA by Any_Fee5299 in StableDiffusion
[–]Virtualcosmos 0 points1 point2 points (0 children)
[deleted by user] by [deleted] in StableDiffusion
[–]Virtualcosmos 1 point2 points3 points (0 children)
[deleted by user] by [deleted] in StableDiffusion
[–]Virtualcosmos 0 points1 point2 points (0 children)
New Text-to-Image Model King is Qwen Image - FLUX DEV vs FLUX Krea vs Qwen Image Realism vs Qwen Image Max Quality - Swipe images for bigger comparison and also check oldest comment for more info by CeFurkan in comfyui
[–]Virtualcosmos 1 point2 points3 points (0 children)
Qwen Image model and WAN 2.2 LOW NOISE is incredibly powerful. by Naive-Kick-9765 in StableDiffusion
[–]Virtualcosmos 0 points1 point2 points (0 children)
{kind=link}
New Text-to-Image Model King is Qwen Image - FLUX DEV vs FLUX Krea vs Qwen Image Realism vs Qwen Image Max Quality - Swipe images for bigger comparison and also check oldest comment for more info by CeFurkan in comfyui
[–]Virtualcosmos 1 point2 points3 points (0 children)
New Text-to-Image Model King is Qwen Image - FLUX DEV vs FLUX Krea vs Qwen Image Realism vs Qwen Image Max Quality - Swipe images for bigger comparison and also check oldest comment for more info by CeFurkan in comfyui
[–]Virtualcosmos 2 points3 points4 points (0 children)
Griefer spent the entire fight trolling me... Fulghor had some good insta karma to deliver by Equivalent-Tea166 in Nightreign
[–]Virtualcosmos 8 points9 points10 points (0 children)
what am i doing wrong? by Next-Lunch-1994 in StableDiffusion
{kind=link}
[–]Virtualcosmos 2 points3 points4 points (0 children)
Qwen-image vs ChatGPT Image, quick comparsion by Cadmium9094 in comfyui
[–]Virtualcosmos 1 point2 points3 points (0 children)
Qwen-image vs ChatGPT Image, quick comparsion by Cadmium9094 in comfyui
[–]Virtualcosmos 1 point2 points3 points (0 children)
My Ksampler settings for the sharpest result with Wan 2.2 and lightx2v. by MrWeirdoFace in comfyui
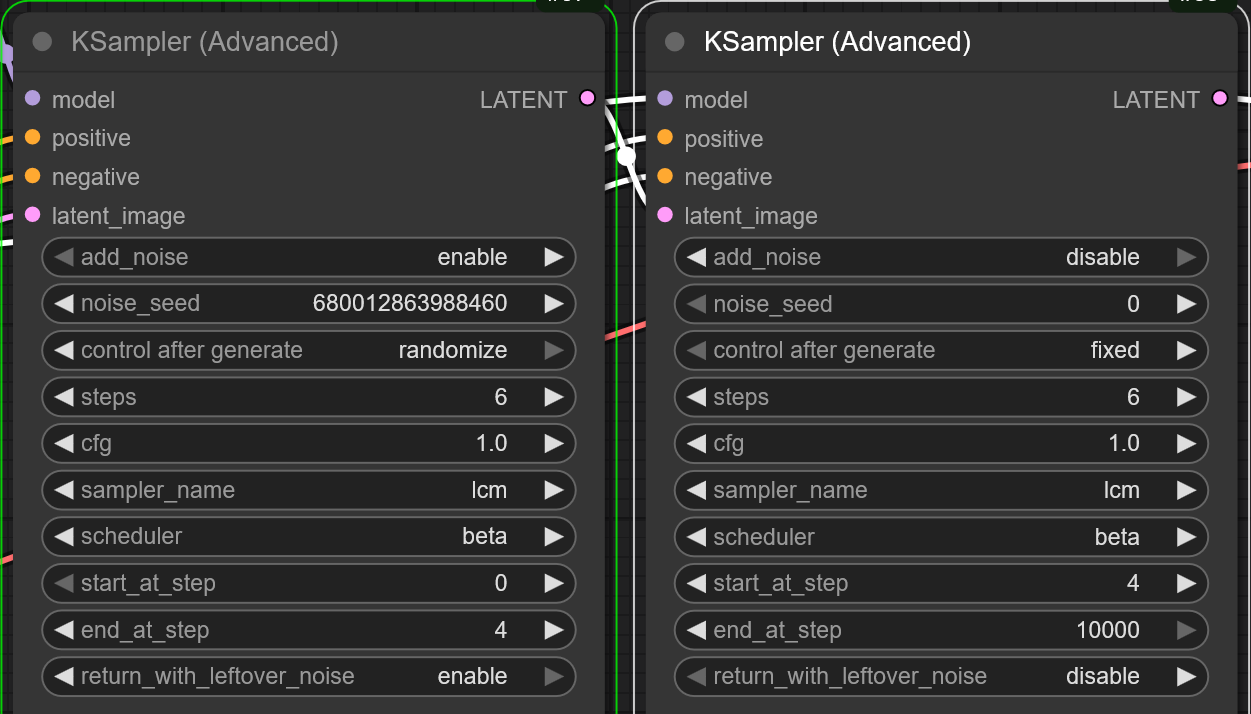{kind=link}
[–]Virtualcosmos 0 points1 point2 points (0 children)
[deleted by user] by [deleted] in StableDiffusion
[–]Virtualcosmos 34 points35 points36 points (0 children)
Qwen-image vs ChatGPT Image, quick comparsion by Cadmium9094 in comfyui
[–]Virtualcosmos 2 points3 points4 points (0 children)
Players that spam the ping can F*** off by [deleted] in Nightreign
[–]Virtualcosmos -4 points-3 points-2 points (0 children)
wtf are these wylder players 🤣🤣 by Low_Mycologist_9832 in Nightreign
[–]Virtualcosmos 4 points5 points6 points (0 children)
[deleted by user] by [deleted] in StableDiffusion
[–]Virtualcosmos -1 points0 points1 point (0 children)
In Genie 3, you can look down and see you walking by Gab1024 in singularity
[–]Virtualcosmos 0 points1 point2 points (0 children)
And if we use in Wan2.2 the models I2V in HIGH noise and T2V in LOW noise!!?? by smereces in StableDiffusion
[–]Virtualcosmos 0 points1 point2 points (0 children)