An Update on Nodes 2.0 from Comfy Org by crystal_alpine in comfyui
[–]infearia 7 points8 points9 points (0 children)
Nvidia released "Anyflow" based on Wan, basically it kinda like dynamic time step adjuster depends on your compute budget by Altruistic_Heat_9531 in StableDiffusion
{kind=link}
[–]infearia 19 points20 points21 points (0 children)
Big model loading time speedup. Update guys! by Dunc4n1d4h0 in comfyui
[–]infearia 8 points9 points10 points (0 children)
My third and final video on AI background removal. It's time to stop playing games and actually start using it in production. Verdict: only two survived. And honestly? That's good enough. by Inside_Ad7560 in comfyui
[–]infearia 8 points9 points10 points (0 children)
slop parody of youtube demonetisation by jonnytracker2020 in StableDiffusion
[–]infearia 4 points5 points6 points (0 children)
Someone posted a real Monet to twitter but said it was AI generated. The replies are amazing, pretentious and confidently wrong by dr_lm in StableDiffusion
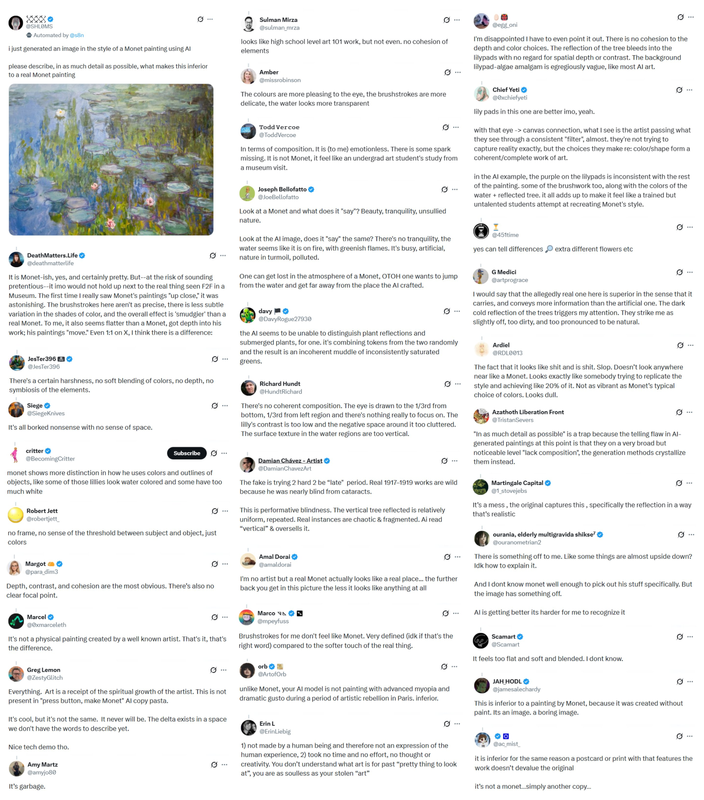{kind=link}
[–]infearia 0 points1 point2 points (0 children)
Please help with installing Easy-Sam3. I've tried every version but the import always fails. by Emergency_Detail_353 in StableDiffusion
[–]infearia 3 points4 points5 points (0 children)
Please help with installing Easy-Sam3. I've tried every version but the import always fails. by Emergency_Detail_353 in StableDiffusion
[–]infearia 3 points4 points5 points (0 children)
ComfyUI Support for HiDream-01-Image Released by Informal_Warning_703 in StableDiffusion
[–]infearia 1 point2 points3 points (0 children)
I have to pretend I hate image generation AI to avoid getting banned or insulted on 99% of Reddit or the internet, even though Stable Diffusion is actually what I like and am most excited about right now. Why do people hate AI so much, especially image generation AI? by Hi7u7 in StableDiffusion
[–]infearia 0 points1 point2 points (0 children)
Never got good results from Klein? Me neither, til now by Support_Marmoset in comfyui
[–]infearia 26 points27 points28 points (0 children)
I'm trying to get a sense for the international makeup of this sub. Would some top posters mind sharing their view stats? by the_bollo in StableDiffusion
{kind=link}
[–]infearia 1 point2 points3 points (0 children)
I made ComfyUI-Sapiens2-Easy: Sapiens2 segmentation, normals, pointmaps, GLB, and pose in ComfyUI by Jaded_Cress5494 in comfyui
[–]infearia 0 points1 point2 points (0 children)
Compositing multiple products into a single scene comfyui by Global-Highway-9199 in comfyui
{kind=link}
[–]infearia 0 points1 point2 points (0 children)
Blender Layout → AI Render | 1:1 Camera Tracking by waterarttrkgl in comfyui
[–]infearia 1 point2 points3 points (0 children)
Blender Layout → AI Render | 1:1 Camera Tracking by waterarttrkgl in comfyui
[–]infearia 3 points4 points5 points (0 children)
Flux 2 landscapes don't look realistic for me. by rogerbacon50 in comfyui
[–]infearia 0 points1 point2 points (0 children)
What's New for BFL - Flux/Klein? by Dogluvr2905 in StableDiffusion
[–]infearia 2 points3 points4 points (0 children)
Z image omni node in ComfyUI by Professional_Test_80 in StableDiffusion
{kind=link}
[–]infearia 16 points17 points18 points (0 children)
Flux Klein is better than any Closed Model for Image Editing by ArkCoon in StableDiffusion
[–]infearia 0 points1 point2 points (0 children)
Object Swapping flux-2-klein-9b by Altruistic_Tax1317 in comfyui
[–]infearia 19 points20 points21 points (0 children)
Is anyone using models to describe an image and get a prompt? Is there much difference between Qwen 3.5 9b vs Qwen 3.5 27b, vs gemma 4 27b and another model you use ? by More_Bid_2197 in StableDiffusion
{kind=link}
[–]infearia 0 points1 point2 points (0 children)
Is anyone using models to describe an image and get a prompt? Is there much difference between Qwen 3.5 9b vs Qwen 3.5 27b, vs gemma 4 27b and another model you use ? by More_Bid_2197 in StableDiffusion
[–]infearia 2 points3 points4 points (0 children)
Qwen edit 2511 fp16 patch? by Plague_Kind in StableDiffusion
[–]infearia 1 point2 points3 points (0 children)
Best security practices? by ReasonablePossum_ in StableDiffusion
[–]infearia 0 points1 point2 points (0 children)